Benchmarks
We verified validity and scalability of our system using various models and training problems. For all experiments we used 4 bits quantization with 1024 bucket size.
Validation
First, we validated that using quantization with the aforementioned parameters does not affect the training quality.
| ResNet50 | VGG16 | Vision Transformer, base | Transformer-XL | GPT-2 | BERT | |
|---|---|---|---|---|---|---|
| Baseline | 75.8 | 69.1 | 79.2 | 22.81 | 14.1 | 93.12 |
| CGX | 75.9 | 68.9 | 78.6 | 22.9 | 13.9 | 93.06 |
Scalability
Next, we performed the weak scaling experiments on the server with low-bandwidth inter-GPU communication, 8 RTX3090 GPUs. We ran two image classification models: ResNet50 (25M parameters) and Vision Transformer (86M parameters) - on ImageNet and two language models: Transformer-XL base (192M parameters) on wikitext-103 and BERT (335M parameters) on SQUAD We see that CGX allows to achieve up to 100% speedup compared to Nvidia NCCL reaching up to 90% of ideal scaling on 8 GPUs.
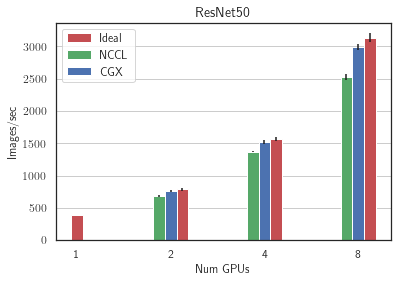
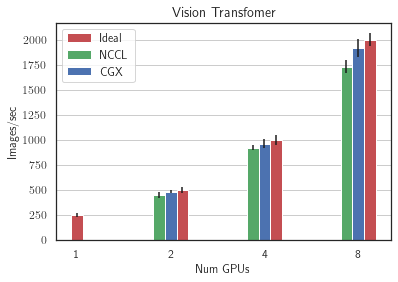
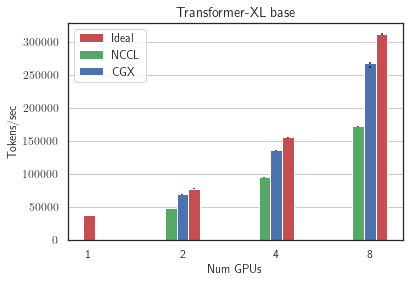
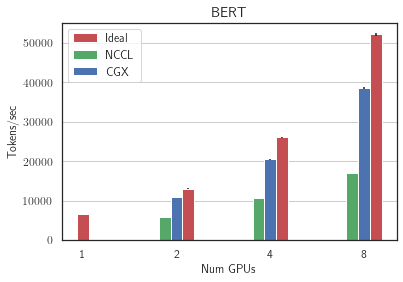
For more benchmarks, please refer to the CGX paper.